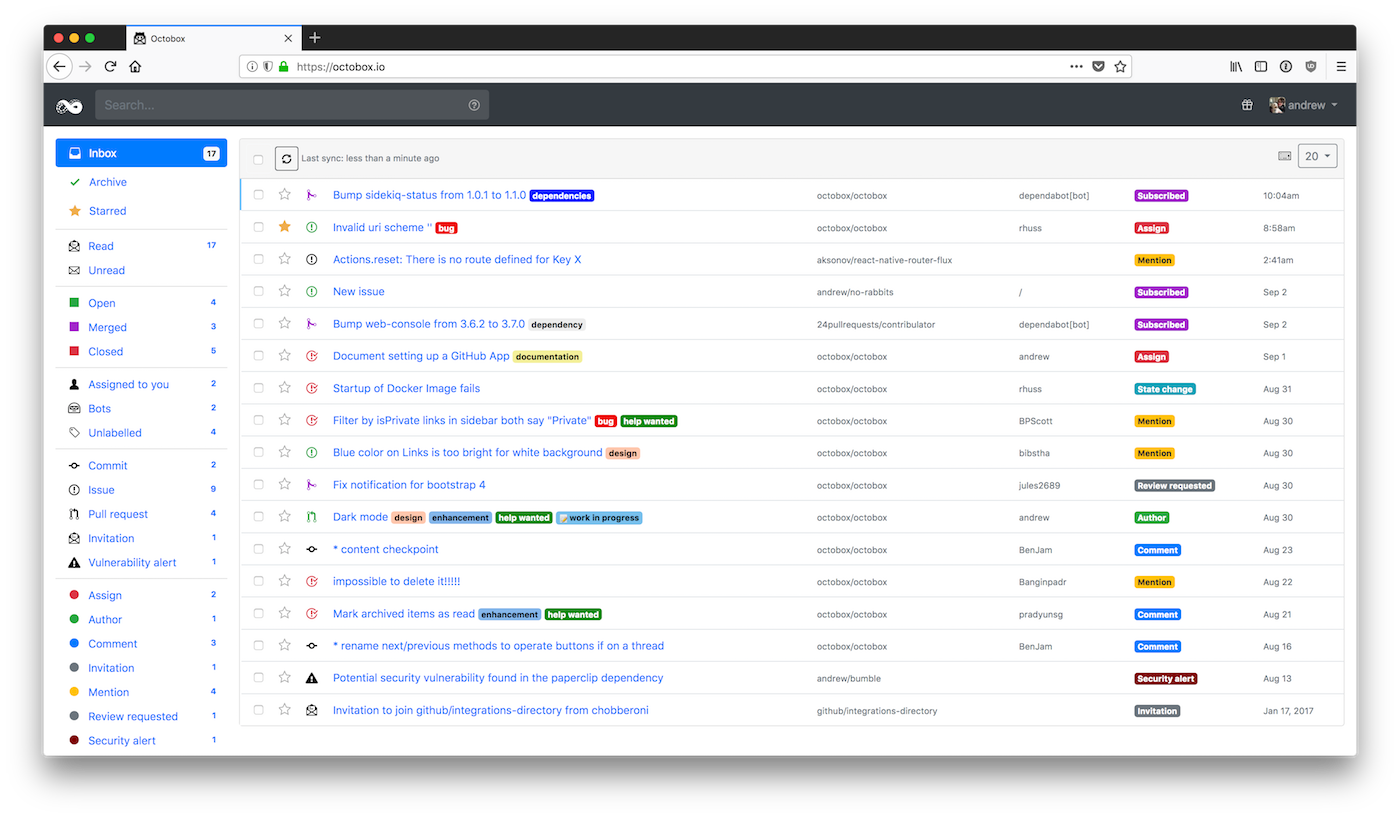
You might think that semantic versioning (SemVer) is the only versioning scheme in open source software, but there’s actually an array of alternatives out there. In this post, I’ve compiled a comprehensive list of the various versioning schemes floating around in the internet, from ZeroVer to SemVer, and everything in between.
Semantic Versioning (SemVer) is probably the most widely used and often assumed default versioning scheme in open source software. It follows the format MAJOR.MINOR.PATCH, where:
- MAJOR version increments indicate incompatible API changes,
- MINOR version increments add functionality in a backward-compatible manner,
- PATCH version increments make backward-compatible bug fixes.
This scheme provides a clear and predictable way to manage and communicate changes in software projects.
Originally proposed by Tom Preston-Werner in 2010, SemVer has since become the de facto standard for versioning in the open source community, used by many package managers and repositories, including npm, RubyGems, and Cargo.
Calendar Versioning (CalVer) is a versioning scheme that uses a date-based version number, typically in the format YYYY.MM.DD. This scheme is based on the idea that version numbers should be human-readable and easy to understand, providing a clear indication of when a release was made.
CalVer offers multiple calendar-based formats to suit different project needs:
- YYYY.MM.DD: Full date (e.g., 2021.03.22) indicating the exact release day.
- YYYY.MM: Year and month (e.g., 2021.03) for monthly releases.
- YYYY.0M.DD: Zero-padded month and day (e.g., 2021.03.05) for consistency in sorting.
- YY.0M.DD: Short year, zero-padded month, and day (e.g., 21.03.05) for compactness.
- YYYY.WW: Year and week number (e.g., 2021.12) for weekly releases.
- YY.0W: Short year and zero-padded week (e.g., 21.05) for a simpler weekly format.
CalVer was proposed by Mahmoud Hashemi in March 2016.
ZeroVer is a satirical versioning scheme where the version number always starts with 0. This convention humorously suggests that software is perpetually in its initial development stages, indicating that it is not yet stable and that APIs are subject to change. Versions might look like 0.1.0, 0.2.0, and so on.
While it’s meant as a joke, many projects unintentionally fall into ZeroVer compatibility simply because they have never made the jump to 1.0.0. This can also serve to set expectations about the software’s maturity and stability during early development.
Version 0.0.1 of ZeroVer was published by Mahmoud Hashemi on 2018-04-01.
Intended Effort Versioning (EffVer) is a versioning scheme that, instead of quantifying the orthogonality of a change, tries to quantify the intended work required to adopt the change. EffVer doesn’t make a distinction between bug fixes, enhancements, and features, as releases often include all of these elements.
Instead, it focuses solely on the effort required for existing users to adopt new versions. The version number reflects the effort needed, with higher numbers indicating more significant changes and potentially greater effort to adopt. This approach helps users better plan for updates by understanding the impact on their workflow.
EffVer was proposed by Jacob Tomlinson in January 2024 as an alternative to SemVer and CalVer, aiming to provide a more user-centric approach to versioning.
Romantic Versioning (RomVer) is a versioning scheme based on Semantic Versioning (SemVer) but attempts to extract the “versioning spec” from real-world usage of software versions, such as those in Node, Rails, PHP, jQuery, NPM, and the Linux Kernel. RomVer follows the format HUMAN.MAJOR.MINOR, where:
- HUMAN is a memorable, human-readable name or word that encapsulates the essence or milestone of the release,
- MAJOR indicates significant, potentially backward-incompatible changes,
- MINOR denotes smaller, backward-compatible updates and bug fixes.
RomVer seeks to enforce some rules to make software versioning predictable and straightforward, helping users better understand the impact of updates. By using human-readable names, it provides a more intuitive way to identify and recall different versions, aligning closely with real-world practices observed in various software projects.
RomVer was proposed by Daniel V from the Legacy Blog crew in 2015.
The term as also used by Jeremy Ashkenas in 2012 in the context of Backbone.js.
Sentimental Versioning takes a whimsical and highly personal approach to versioning. Unlike SemVer, which has a formal specification, Sentimental Versioning provides a guide with some playful suggestions. Key aspects include:
- Creativity and Originality: You should not copy another sentimental versioning system. Instead, create something unique and original.
- Personal Meaning: The version number must be meaningful to you, the author.
- Flexibility: You may explain the system you create if the beauty is enhanced by understanding it, or you may improvise new numbers based on your mood on that day.
Sentimental Versioning encourages a deeply personal and creative expression through version numbers, making each version a reflection of the author’s sentiments and individuality.
Sentimental Versioning was proposed by Dominic Tarr in August 2014.
Hash Versioning (HashVer) is perfect if you are publishing very frequently. The HashVer format consists of 3 or 4 values separated by a period:
- Full year (printf(“%Y”))
- Zero padded month (printf(“%m”))
- [Optional] Zero padded day (printf(“%d”))
- 10+ characters of the current source control commit’s hash
Examples:
2020.01.67092445a1abc2019.07.21.3731a8be0f1a8
HashVer allows for frequent and precise versioning by incorporating both the release date and a unique identifier from the source control system. This makes it easy to track specific builds and changes over time.
Because commit hashes are random, additional granularity like days or a CI build index ensures proper ordering when releasing frequently. This approach allows for precise and traceable versioning by combining the release date with a unique commit identifier.
HashVer was proposed by miniscruff in 2020.
GitDate Versioning is similar to HashVer, addressing issues with Semantic Versioning by using the commit date from a Git repository. This provides clear and precise tracking of changes.
Format: year.month.day.git-short-code
- Examples:
2021.03.22.d31d3362021.03.31.44cf59b12022.02.14.2c52a964
GitDate indicates the release date of each version for easy identification of when a version was created. It allows quick lookup of changes using git compare and provides visibility into the last release for infrastructure teams. Even without git tags, specific versions can be cloned using the format.
However, multiple builds on the same day may require git repository access to determine the order. Additionally, it allows customers to see when the software was last updated.
GitDate was proposed by Taylor Brazelton in June 2022.
Pragmatic Versioning optimizes for communicating changes to package consumers while retaining simple semantics for package maintainers. The format is BIGRELEASE.ANNOUNCE.INCREMENT, where:
- BIGRELEASE indicates major updates or significant milestones controlled by the package author.
- ANNOUNCE communicates notable announcements or changes.
- INCREMENT is a smaller, incremental update for every contribution.
Pragmatic Versioning addresses the challenges faced by package authors, enabling them to maintain old versions and release new ones efficiently. It helps communicate what will be maintained, how to get the most appropriate version, and allows for automatic releases without explicitly labeling each change. This approach ensures clear expectations and effective communication with the user community.
Pragmatic Versioning was proposed by Severin Ibarluzea in December 2023.
WendtVer is a tongue-in-cheek versioning system designed to minimize the thought required for version increments. Starting at 0.0.0, every commit increments the version number following these rules:
- PATCH version increments on every commit.
- MINOR version increments when the next PATCH would be 10, rolling PATCH over to 0.
- MAJOR version increments when the next MINOR would be 10, rolling MINOR over to 0.
Additional labels for pre-release and build metadata are not available as extensions to the MAJOR.MINOR.PATCH format.
This system, while creating chaotic and meaningless version numbers, makes it easy to predict the next version. WendtVer serves as a humorous alternative to Semantic Versioning, emphasizing simplicity over rational versioning practices.
WendtVer was proposed by Brian Wendt in August 2018
SoloVer is a simple and expressive versioning specification that uses a single number with an optional postfix.
Format: <version_number>[<postfix>]
- version_number: A single integer, starting at 0.
- postfix: Optional, matching regex
[+-][A-Za-z0-9_]+.
Rules:
- Increment the version number for each new release.
- Postfixes can be added for extra context.
Precedence:
- Higher numbers follow lower numbers.
+ postfixes come after no postfix (for hotfixes).- postfixes come before no postfix (for pre-releases).- Postfixes are sorted alphanumerically; longer ones come last.
SoloVer does not communicate “backward compatibility” and focuses on simplicity and expressiveness, leaving compatibility documentation and testing to the provider and user.
SoloVer was proposed by beza1e1 in March 2024.
Break Versioning (BreakVer) aims to fix several issues identified with Semantic Versioning (SemVer). BreakVer addresses the complexity of SemVer’s lengthy specification and its lack of distinction between major and minor breakages.
BreakVer aims to be easy to follow strictly, making it more reliable in practice. It emphasizes the maximum potential impact of version updates, ensuring clear communication about the safety of upgrades.
BreakVer Specification:
- Format:
<major>.<minor>.<non-breaking>[-<optional-qualifier>]
- major: Major breaking changes or significant non-breaking changes.
- minor: Minor breaking changes or minor non-breaking changes.
- non-breaking: Strictly no breaking changes.
- optional-qualifier: Tags like
-alpha1, -RC2, etc.
Version Bumps:
- non-breaking: Always a safe upgrade.
- minor: Check the CHANGELOG for minor breakages.
- major: Check the CHANGELOG for major breakages.
BreakVer was proposed by Peter Taoussanis in August 2015 as part of the encore clojure library.
Explicit Versioning:
Explicit Versioning is a specification for developers who care about releasing software with clear, explicit announcements of intended breaking changes. It uses an extra required identifier to handle intentional incompatible changes.
Specification Schema:
Explicit Versioning uses a schema composed of four identifiers, represented as:
Disruptive.Incompatible.Compatible.Fix[-Optional_Identifiers]
Key Differences from SemVer:
- Isolation of Incompatible Releases: Isolates any intentional incompatible release from other types of releases.
- Disruptive Situations: The most left number is only incremented when a disruptive situation occurs in the software, not for minimal backward incompatible changes.
- Clarity and Precision: Reduces ambiguity in the usage and interpretation of the versioning schema.
This approach ensures that any significant, intentional changes are clearly communicated, providing a more precise and unambiguous versioning system for developers and users.
Explicit Versioning was proposed by Paulo Renato in February 2017, more details can be found in the Announcement Post.
Zen Versioning (ZenVer) is a revolutionary, simple, and straightforward versioning specification. Unlike Semantic Versioning, ZenVer demands nothing from the developer and less from the end-user. The idea is clear: number go up, software go new.
Larger is greater, greater is larger. Larger number means better software.
Specification:
Given a version number VERSION, increment the:
VERSION when you make incompatible API changes.VERSION when you add functionality in a backward-compatible manner.VERSION when you make backward-compatible bug fixes.VERSION when you change practically anything.
No additional labels, titles, or subtitles for pre-release and build metadata should be appended to the VERSION format. Such metadata can be used outside the version string but should be avoided in package meta information.
ZenVer was proposed by NotAShelf in May 2024.
Package Versioning Policy (PVP) is a versioning scheme designed specifically for the Haskell ecosystem to manage package dependencies and ensure compatibility. It provides a formal specification for version numbers to help developers and users maintain and use Haskell packages effectively.
Version Number Format: A.B.C
- A.B: Major version number.
- C: Minor version number.
Rules:
- Breaking Changes: If any entity is removed or altered in a way that could break compatibility, increment the major version (
A.B).
- Non-Breaking Changes: If only new bindings, types, or classes are added without breaking existing functionality, increment the minor version (
C).
- Minor Updates: For minor, non-breaking updates like documentation corrections, other components of the version may change, but
A.B.C can remain the same.
Principles:
- Isolation of Incompatible Releases: Major version increments isolate incompatible changes, ensuring clarity for users about potential breaking changes.
- Disambiguation: Clear rules reduce ambiguity in how versions are incremented.
- Consistency: Ensures consistent dependency specifications to avoid build and compatibility issues.
PVP is specifically tailored to the Haskell ecosystem, differing from Semantic Versioning (SemVer) by not using a special meaning for 0.x.y versions and not supporting version tags or build metadata.
PVP was proposed to the Haskell community by Bulat Ziganshin in 2006, three years before SemVer, on the Haskell mailing list.
FloatVer is a versioning scheme that uses non-negative IEEE754 32-bit floating point numbers in base-10 format. FloatVer is natively supported by the majority of programming languages, CPUs, and GPUs. Some example FloatVer version numbers are 0.7 and 290.10008.
Version Number Format: breaking.nonbreaking
- breaking: incremented by 1 for backward-incompatible changes
- nonbreaking: incremented for backward-compatible changes
- Purely
nonbreaking changes MUST NOT increment the breaking part of the number.
- Breaking changes MAY change the
nonbreaking part of the number to any value.
- Leading and trailing zeros are ignored, except in the case of
0.0.
0.0 is the minimum version and starting point for all FloatVer projects.340282346638528859811704183484516925440.0000000000000000 is the largest possible version supported by FloatVer.
In the context of FloatVer, “backward-compatible” means:
- no semantic changes to existing functionality
- an updated existing feature uses no more memory, time, or cores than its previous version
- the software takes up no more than 1.5 times the space of the previous version
These rules ensure that nonbreaking versions permit safe automatic upgrades. FloatVer was proposed by Alex Shroyer in July 2024.
AsymptoVer
AsymptoVer – yes, I’ve just made up that name – is a peculiar, maybe even esoteric, versioning scheme.
It was popularized by Donald Knuth (see also Errata on the book series Computers & Typesetting).
Version numbers are decimal numbers that asymptotically approach a number with an infinite decimal expansion (usually an irrational number).
Examples:
If you feel like joking: There are plenty irrational algebraic numbers and transcendental numbers available.
If you know of any other versioning schemes that should be on this list? Let me know on mastodon or submit a pull request to GitHub.
Some other versioning related links:
]]>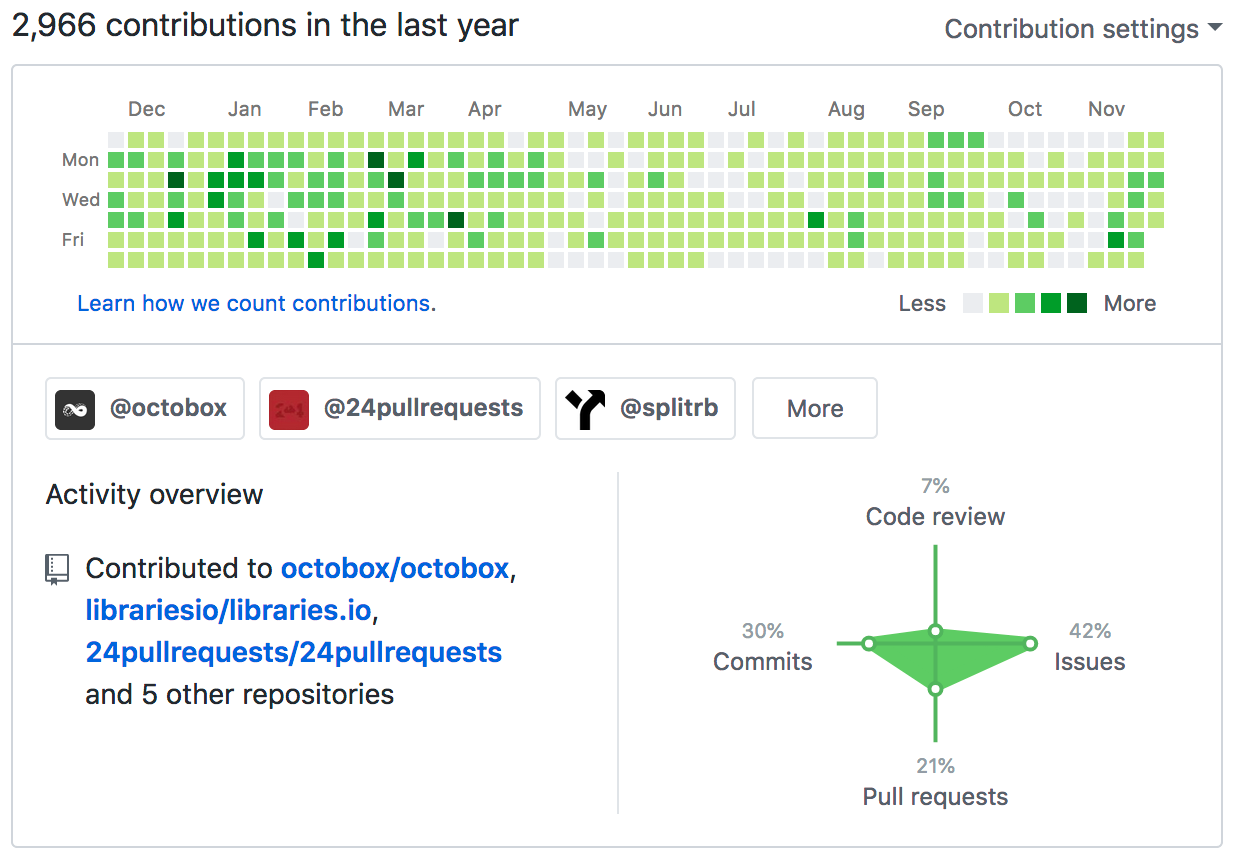 GitHub profiles don’t show the full picture of open source contribution
GitHub profiles don’t show the full picture of open source contribution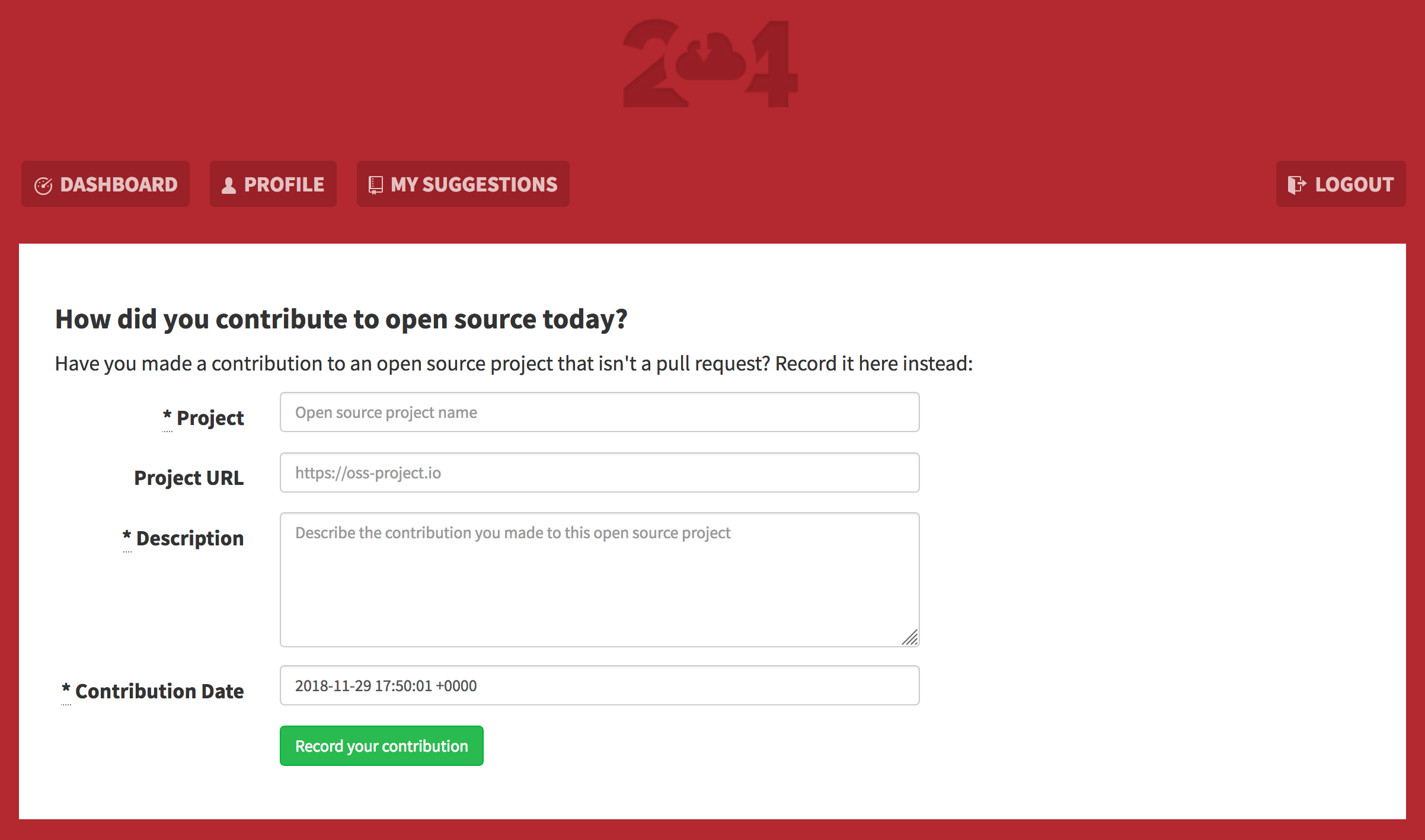 The new 24 Pull Requests contribution form
The new 24 Pull Requests contribution form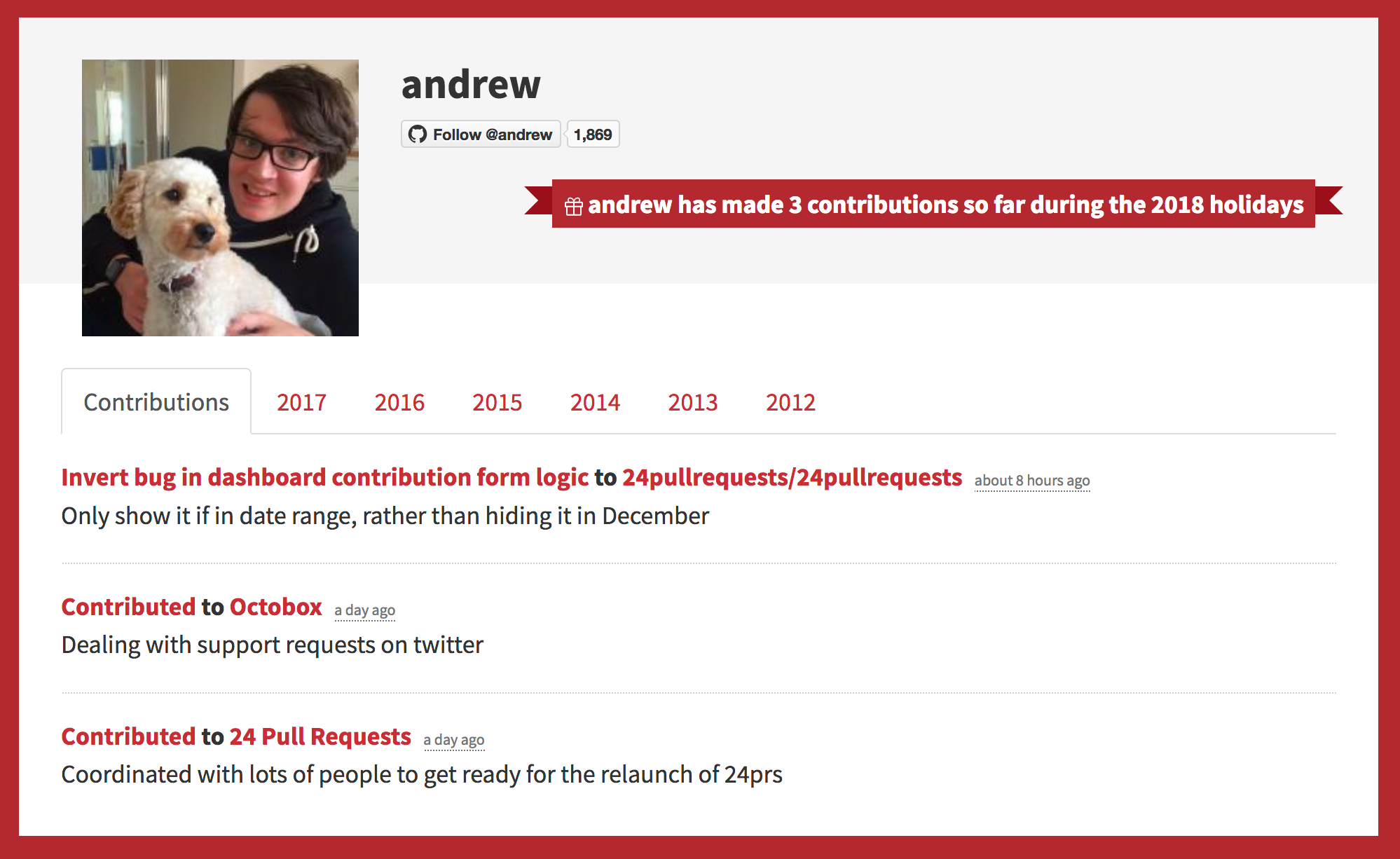 User profile page showing a mix of pull requests and non-pull request contributions
User profile page showing a mix of pull requests and non-pull request contributions